In this column, I’ll review what user assistance architects mean by reuse and what its benefits can be. I’ll then describe some different scenarios for reuse and offer guidelines that user assistance architects and information developers can follow. My examples show how DITA (Darwin Information Typing Architecture) can be an effective reuse framework. But the principles I discuss go beyond DITA, and you can apply them to any structured information framework or toolset.
Reuse Defined
Again recalling the early days of the personal computer, at the time, the only application I could think of that would justify owning a home computer was that we could store our recipes on it. I’m not sure anyone actually did this, but that’s all we could come up with initially. So, in that vein, let me share my favorite grits recipe, one I call DITA Grits Casserole. In fact, let me share two versions of this recipe, one for Southerners and one for non-Southerners. Note that the only difference is the “Results” section at the end.


Well, that’s a lot of typing to produce two versions that differ only by a single sentence. One way I could minimize the work would be to create the original and save it as southern_grits.doc, then copy and paste the common text into a second file called yankee_grits.doc, where I could then add the differentiating results statement. This example would be like our original, primitive approach to reuse, which comes with a lot of headaches. For one, what happens when my editor points out that DITA, as an acronym, needs to be in all caps? I have to find the original version and the alternate version and fix it in both places. And what if I want to translate both versions? Will I have to pay twice to have all the common text retranslated?
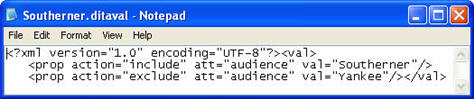
A better solution is to have only one file that both contains the common text and specifies conditions for the variable text. Figure 4 illustrates this common technique, which is often called conditionalized text.

This example, which uses conditional text, embodies what we mean when we talk about reuse as a documentation strategy—specifically:
Reuse is the refactoring of content in an automated way, so we can use it in multiple documents or multiple media formats, without significant intervention by the author.
We can quickly see the benefits of reuse that meets this definition:
- write once, use many—We could include the same file in regional cookbooks, generating the Southern version for the appropriate regions and the non-Southern version for other regions that have not yet developed the proper palate for grits.
- edit once, fix many—Fix that nasty little capitalization issue in the source file and know it will be correct in all of the books that use that file.
- translate just once—We can eliminate the unnecessary retranslation of text that is common across multiple topics.
- write once, output many—Since the DITA source is in XML, we can use the same file to do an online cookbook in HTML and a printed cookbook using PDF formatting.
- get it right, keep it right—Reuse is particularly useful for golden text scenarios where you need to control the message—for example, pointing out that feature X could erase users’ hard drives if they accidentally introduced a typo in its command. Once you get marketing and the lawyers to agree on the acceptable wording, you can lock it down.
Types of Reuse
The reuse landscape is more complicated than just producing the same document in multiple formats. In fact, that is probably the least useful application for reuse. To plan and write effectively for content reuse, you must first understand the different ways in which you can reuse content and the unique considerations for each of them. There are four scenarios for content reuse:
- same content published in different media—In this case, the unit of reuse is the entire document.
- same topic in different documents—In this case, the unit of reuse is the topic.
- same content within many topics—In this case, the unit of reuse is the smallest taggable element.
- slightly different content within one topic—Again, the unit of reuse is the smallest taggable element.